又有一件「新聞」可以來順道談一些文字編碼的東西了。
這次的事件是這個:2021/9/22 數位五倍券開放登記當天,由於剛開啟時是人最多的時候,有不少人看到這樣的錯誤訊息:
甇斗�滚�嗵�⊥�蓥蝙�鍂��
這是個很標準的編碼錯誤,而由大約一半的字是�來看,這有可能是 UTF-8 被當成 DBCS 編碼造成的。查了一下編碼表,容易發現前兩個字可以湊出東西來:
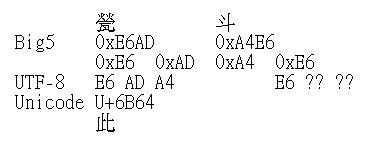
下一個字是未知的�1,這也很容易理解原因:下一個位元組有一半機率是 0x80~0x9F,除非外字集補字否則這個區段是沒有字的。再下一個字就有點麻煩了:這個字是「滾」的簡字,所以並沒有收錄在一開始的 Big5 當中。
好吧,那或許是個比較流行一點的外字集?UAO (Unicode 補完計畫) 把這個字放在 0x86D3--等等,事情不太對勁了。UTF-8 如果出現 0xD3 表示這是個 2 bytes 的字,代表的字碼範圍是 U+04C0~U+04FF,這塊區域是西里爾字母的變種--一個中文系統的錯誤訊息居然出現西里爾字母?這一定有哪裡不對勁。
各種 Big5
問題顯然出在「比較流行一點的外字集」這件事上。
最早的 Big5 其實是業界標準,並沒有經過詳細考慮說要收什麼字不收什麼字;於是在流行起來之後,各個地方就根據自己的需要在造字區裡開始造字。於是就會碰到資料交換的一個最根本的問題:你的造字因為我沒有定義所以我看不到、或是變成碰巧我放在同個位置的字。
因此,使用共同的造字區定義就變成一件很重要的事情。維基百科的大五碼條目中,〈Big5 延伸〉段落就列了許多種曾經有不少使用者的造字區定義;有許多後來的定義甚至建基在之前已經足夠流行的定義上。我前面提到的名詞「外字集」指的基本上就是一套在造字區放了一些原本字集沒有收錄的字--外字--的定義。
而流行的外字集可不只有 UAO 一套。有另一套也很多人在用的 Big5 延伸字集叫做 HKSCS,對造字區域的定義和 UAO 是很不一樣的。剛才看到的「滚」字,在 HKSCS 裡是編在 0x8DE5--出現是中文字範圍的 UTF-8 位元組了2,所以可以推斷這裡用的對照表某個程度上是和 HKSCS 相容的。
就用 HKSCS 來細看這些亂碼字吧:(我使用的是 HKSCS 2001 的字表,比較新版的應該差別不大)

位元組看起來足夠合理,而且能夠直接讀出兩個中文字來了;U+?528 這個字也很好解決,如果是中文字的話 ? 只會是 3~9,就把七個字都試試看:
| U+3528 | U+4528 | U+5528 | U+6528 | U+7528 | U+8528 | U+9528 |
| 㔨 | 䔨 | 唨 | 攨 | 用 | 蔨 | 锨 |
看起來是 U+7528 的「用」字。中間的四個未知字則比較麻煩,因為未知的部份有 6 個位元,有 64 個可能字要檢查。
可以注意到,我上面的表裡把未知字都只指定一個位元組。這是根據已知的位元組組合給定的:要讓 0x8DE5 的 0x8D 能夠是一個 UTF-8 的延伸字,它前面的未知字只會是一個位元組,這樣才能讓它成為 0xE6 的延伸。也就是說,這個解碼的演算法並不是固定抓兩個位元組成字後找對照表,而是一個位元組一個位元組的找,如果找到無法成字的兩個位元組則丟棄前面那個位元組,將後面的位元組再次嘗試往後組字。
對 0x8D 來說因為 0x**8D 絕對不會是字,所以不論前面是 0x80~0xBF 的哪一個都無法成字,因此這裡會出一個�很合理;同樣地第二個未知因為是 0x99,同理無法成字,因此也出了一個�。但第三個就有趣了:�後面是 0xA1,這是一個合法的後半位元組,所以前半位元組並不是任何字都有可能,而是真的 0x**A1 就是沒有字所以無法成字--可是,HKSCS 對於沒有指定字的位置都分配了 Unicode 的 PUA 區對應,所以應該會出現空白而不是�才對。除非,這個位元組是 0x80,這是不管哪個 Big5 標準都沒有定義的位置;但是這樣放進去之後的 UTF-8 代表 U+7021,是「瀡」字--這就又不通了。
看來這裡被解錯的編碼是個跟 HKSCS 大致相容但不完全一樣的 Big5 編碼。
真正的原因
好啦,該是揭曉謎底的時候了:其實我在噗浪上看到這個亂碼時,同一個噗的討論裡已經有人把正確的錯誤訊息給貼出來了:「此服務無法使用。」因此上面這一大篇其實是事後反向檢查的結果。對於有問題的第三個�,這個字是 U+7121「無」字,也就是這神秘的第三個�位元組是 0x84。但為什麼 0x84A1 無法成字?
這是因為:這被解錯的 Big5 版本是近期的一個整理 Big5 結果的編碼,以 HKSCS 為基底但沒有 PUA 區對應。這是 WHATWG 的 Encoding Standard。
我之所以會知道這個還是得感謝 MozTW 的整理。那邊有簡單的介紹了目前已知的 Big5 編碼及其延伸,以及這些各個編碼的對照表;在這系列文章還是草稿時,我也是從這裡知道原來已經有很多人進行過把這一堆 Big5 延伸編碼進行整合的嘗試及結果的。
那裡面對 WHATWG Encoding Standard 的項目裡有這麼一句話:
此字碼表在 2015 年 9 月 11 日進入 Firefox 43,成為目前使用的 Big5 編碼 (Bug 912470)。
真相終於大白了:原來這是因為把這串 UTF-8 解成 Big5 的程式是 Firefox,它看到沒有指定編碼的文字會使用 (可能是系統) 所設定語系的編碼解碼,因此而使用了 WHATWG Encoding Standard 所定義的和 HKSCS 相容的 Big5 轉換表,才會出現特定的這些字的。根據這個標準定義,它的解碼演算法正是上面所描述的:兩個位元組組不成字時前一個位元組輸出�,後一個位元組會再次嘗試組字;而這個轉換表所定義的第一個字是 0x8740,因此 0x84A1 未定義不成字,第三個�才會這樣輸出。
最後一個補充:這串最後的兩個�從這裡看其實是完全沒有資訊的。照樣反向推論的話,那個錯誤訊息的最後一個字是句號 U+3002,UTF-8 編碼為 0xE3 0x80 0x82,這是 WHATWG 標準無論如何都無法成字的組合;至於為什麼只出現兩個�我就不是很確定了:比較可能的解釋是 0x80 不被做為前半字元看待,所以兩個�對應的是 0xE3 和 0x82 兩個位元組,0x80 就被吃掉了。
小結
是的,這篇文章其實是藉這個偽解碼過程簡單談了一下 Big5 的各種變種。這方面的研究和歷史沿革我比較不是很熟,大多數還是靠維基百科和 MozTW 那個網頁裡的整理資訊 (HKSCS 2001 的對照表也是從那裡拿來用的),所以要比較詳細一點的簡介的話還是推薦大家前往那邊。
如果可以的話其實這篇我有點想照之前的慣例排在星期三中午發的,但事件發生是個星期三早上,我看到時已經是下午了,如果要排在下個星期三發的話離事件又有一點遠;加上這裡最近都沒什麼文章,所以就決定乾脆排在完稿之後的下一個中午發了 XD
註腳
- 這個符號經常用在轉碼失敗的字上,表示這裡有個或有些位元組不成字。單獨打出這個字的話它是 U+FFFD Replacement Character,顧名思義它就是用在「代替」表示出問題的位元組的字。這篇文章中的這個字都是我自己貼這個代替字上來的,沒有任何轉碼發生 XD ↩︎
- 之前提過,常用漢字範圍是 U+4E00~U+9FFF;如果範圍拉廣一點,納入自 U+3000 開始的範圍的話,還能納入東亞文字標點、日文假名、中文注音、韓文諺文相容字母 (一般的韓文諺文單音是在 U+1100~U+11FF,組成字的諺文則是 U+AC00~U+D7FF)、以及漢字擴展 A 區等範圍。這塊區域 (U+3000~U+9FFF) 編成 UTF-8 的時候,第一個位元組會是 0xE3~0xE9,因此這個範圍的位元組是很有用的一個判斷 UTF-8 字串有沒有漢字語言的判準。(用在韓文上的判準則是 0xEA~0xED,是由幾行前提到的範圍以同樣方式求出來的;這四個裡面 0xEA 可能不太準,但 0xEB 和 0xEC 一定是韓文,如果不是第四篇裡提到的 CESU-8 的話那 0xED 也一定是韓文。) ↩︎